· curso de desenvolvimento de software para iniciantes · 22 min read
Introdução a versionamento de código e conhecendo o Git
Vamos entender sobre versionamento de código e aprender os conceitos básicos de Git na prática!

No artigo anterior tivemos uma introdução ao terminal, confere aqui: Introdução ao terminal.
Introdução a versionamento de código e Git
Durante o desenvolvimento de software o que fazemos é escrever arquivos. Arquivos estes que são compilados para código de máquina e rodam no nosso sistema operacional ou interpretados por um programa interpretador da linguagem de programação, como o Node.js que executa nossos arquivos da linguagem de programação JavaScript, mas no fim das contas são só arquivos.
Imagina um trabalho de escola ou de faculdade, onde escrevemos um documento para enviar aos nossos professores. Este arquivo tem versões, pois, quando escrevemos ele, começamos fazendo um pouco hoje, outro tanto amanhã, o restante depois, até chegar na versão final e entregarmos aos professores.
O mesmo acontece com código de programas: desenvolvemos o sistema em pequenos pedaços entregáveis e cada entregável é uma versão do nosso software.
Vamos pensar no exemplo de um site. Este site possui um menu superior, um logotipo da nossa marca no centro da tela, duas caixas de conteúdo logo abaixo e um rodapé com diversos links úteis ao visitante. Ao desenvolvermos este site, podemos fazer o menu superior e salvar uma primeira versão, depois adicionamos o logotipo ao centro e salvamos mais uma versão, colocamos uma ou as duas caixas de conteúdo (dependendo da complexidade delas) e então salvamos outra versão, por fim adicionamos o rodapé e temos a versão entregável do site.
Deste modo outras pessoas também poderiam trabalhar em nosso projeto e continuar a partir do ponto onde paramos.
Isso é versionamento de código.
Em um trabalho de escola/faculdade podemos criar os documentos do Word ou Excel e nomear eles como: trabalho-de-historia-1.docx, trabalho-de-historia-2.docx, trabalho-de-historia-agora-vai.docx, trabalho-de-historia-acaba-logo.docx. Mas em uma base de códigos de um software não dá para fazer isso.
Os softwares possuem milhares de linhas de código e arquivos e temos que tomar muito cuidado com cada alteração feita ali. Um bug (problema) inserido em uma versão do nosso software pode nos causar estragos terríveis; desde financeiros, como um ecommerce deixando de vender, uma empresa com as máquinas paradas, até vidas, como o controle de oxigênio em hospitais ou uma falha em um carro autônomo.
Por isso é importante que consigamos voltar a versão anterior do nosso software facilmente e para que isso seja fácil, somente tendo um bom controle de versão. Ter a pasta do sistema chamado de sistema-v1, sistema-v2 não diz nada sobre o que foi alterado naquela versão.
Existem diversas ferramentas que podem nos ajudar no versionamento de código, mas a mais utilizada hoje em dia, devido a sua eficiência, é o Git.
O que é Git
O Git é um software de linha de comando, assim como os que conhecemos no artigo introdução ao terminal. Ele é instalado em nosso sistema operacional e fica disponível para utilizarmos via terminal.
Existem ferramentas gráficas que podemos utilizar para gerenciar projetos versionados com Git, mas vamos focar aqui em entender como ele funciona antes de aprender essas ferramentas.
Com o Git nós podemos criar versões do nosso sistema ou voltar para versões anterior facilmente, assim como analisar o histórico do que já foi feito.
Vamos olhar um exemplo de projeto versionado com o Git.
O dunders é um template para Jekyll, um gerador de sites estáticos em Ruby que eu utilizo em meu blog pessoal. Ele possui hoje 70 commits, ou seja, 70 versões diferentes dele. Não se apegue a palavra commit agora, vamos entender isso mais para frente. Por enquanto saiba que um commit é uma versão do que fizemos.
Caso eu queira voltar a versão do meu projeto para o que eu fiz na versão 69, basta eu rodar um comando no Git e pronto… Tudo volta a ser como era antes.
Instalando o Git
Com essa rápida introdução a versionamento de código e Git fica complicado entender, mas com a prática tudo ficará mais claro em sua mente.
Se você estiver utilizando Windows, não se esqueça de utilizar o cmder, que comentei no artigo de introdução ao terminal. Basta entrar em cmder.net e seguir com a instalação.
Antes de tudo precisamos instalar o Git em nossa máquina. Devemos entrar em git-scm.com e seguir com a instalação para o nosso sistema operacional. Basta procurar por download no site. Se quiser também pode entrar direto aqui: git-scm.com/downloads.
O passo a passo para instalação do Git se encontra no próprio site. Você pode seguir por lá de acordo com seu sistema operacional e depois voltar aqui.
Configurando o Git
Depois de instalar o Git, você pode rodar o comando git --version para verificar se está tudo OK. Se você não receber o retorno como a versão do Git instalado em sua máquina, então aconteceu algo errado na instalação e é necessário refazer isso.
Para que o Git consiga carimbar cada versão que fecharmos com nossas credenciais (nome e email), precisamos configurar isso.
Então vamos rodar os seguintes comandos em nossa máquina:
Primeiro seu nome.
git config --global user.name "SEU NOME"Agora seu email.
git config --global user.email "seu.email@provedor.com"Com isso feito, o Git está configurado e pronto para ser utilizado em sua máquina.
Sempre que você for utilizar o versionador em outras máquinas, será necessário configurar seu nome de usuário e email. Se você quiser, pode copiar o arquivo .gitconfig que fica localizado em sua pasta de usuário (Users\Nome de Usuário no Windows ou /home/usuario no Linux) e colar no mesmo local em outras máquinas.
Eu carrego o meu .gitconfig para todas as máquinas e você pode ver ele aqui para entender como é a estrutura de um arquivo de configuração do Git.
Entendendo sobre versionamento
Para entender de fato o sobre versionamento e sobre o uso do Git, será necessário compreender alguns termos, como “repositório”, “commit”, “branches”, etc.
Vamos primeiro entender os termos básicos e mais importantes e depois partimos para a prática.
Repositórios Git
Um repositório nada mais é que uma pasta onde estão todos os arquivos do nosso projeto, incluindo nosso versionamento.
Podemos criar um repositório ou baixar ele de alguma hospedagem de repositórios Git.
Normalmente trabalhamos com repositórios hospedados em algum lugar, como um servidor ou algum serviço de hospedagem, pois trabalhamos em grupos que podem ir enviando suas alterações para o projeto e cada outra pessoa pode baixar essa alteração em sua máquina.
Isso é uma característica legal do Git: nós trabalhamos de modo descentralizado de desenvolvimento, onde cada pessoa possui uma versão inteira do repositório em sua máquina e só envia os pedaços que alterou para um local onde todo mundo pode baixar essas alterações, porém conseguimos trabalhar até mesmo sem internet e depois enviamos o que fizemos.
O que é um commit
Commits são como fotos da última versão do nosso código. Eles carregam tudo o que foi alterado em nosso projeto para que, quando precisarmos, possamos voltar ao commit onde possuíamos a versão que gostaríamos de utilizar.
A cada nova alteração que fazemos, que seja uma versão do nosso software, podemos fechar um commit e guardar isso no histórico do nosso projeto.
Histórico
O histórico é a união dos nossos commits. A cada novo commit, temos uma nova versão do projeto e tudo isso fica agrupado no histórico do Git.
Branches
Branches são uma maneira de organizar o nosso trabalho com versionamento de código. Nós possuímos uma branch chamada master e nesta branch temos a versão oficial do nosso projeto. Quando vamos fazer uma alteração, podemos criar uma ramificação da master e trabalhar somente nela, sem afetar o código oficial. Ao finalizarmos nosso trabalho na nossa ramificação, então podemos juntar o nosso trabalho com a master.
Será mais fácil entender quando estivermos praticando, porém podemos pensar no seguinte exemplo:
No meu blog eu já utilizei WordPress, uma ferramenta para criação de blogs, depois eu migrei de WordPress para Hexo.js, um gerador de sites estáticos e em seguida migrei de Hexo.js para Jekyll, outro gerador de sites estáticos.
O meu blog sempre foi versionado no Git e guardado no GitHub, uma hospedagem de repositórios Git que vamos conhecer mais para frente.
Quando eu queria migrar de Hexo.js para Jekyll a estrutura de arquivos inteira iria mudar, assim como a criação de um novo tema. Eu não poderia fazer tudo isso de uma só vez e então fechar um commit, pois isso seria a mesma coisa que não versionar. Então o que fazemos é criar uma nova branch onde será feita a migração, trabalhamos somente nesta branch e nada é alterado no meu site, quando o trabalho estiver finalizado, então juntamos os commits feitos nessa nova branch com a master.
Imagine branches como pastinhas onde ficam armazenadas nossos commits. Se eu fizer um commit na nova branch e não juntar com a master, esse commit nunca virá para a versão oficial do meu blog. Cada branch carrega seu próprio histórico e nós só transformamos isso em uma história oficial quando juntamos com a branch oficial (neste caso a master).
master
|_commit 1
|_commit 2
\
nova-versao-do-blog
|_commit 1 (que veio da master)
|_commit 2 (que veio da master)
|_commit 3
|_commit 4Quando criamos uma nova branch, ela é, inicialmente, uma cópia de outra. Neste caso é uma cópia da master. Então ela carrega todos os commits da master e a partir daí teremos novos commits inseridos somente na nova branch. Ao juntarmos tudo, então temos a versão final do projeto.
master
|_commit 1
|_commit 2
|_commit 3 (veio da outra branch)
|_commit 4 (veio da outra branch)Inicializando um repositório Git local
Agora que entendemos o que são repositórios, branchs, histórico e commit, podemos começar nossos trabalhos práticos.
Vamos começar criando uma pasta para trabalharmos dentro dela com os comandos que aprendemos no artigo de introdução ao terminal. Vamos chamá-la de workspace. Para isso vamos utilizar o terminal. Abra o terminal e digite o comando:
mkdir workspaceE agora acesse essa pasta com o comando:
cd workspacePara que essa pasta se torne um repositório Git, precisamos rodar o comando git init.
Quando iniciamos um repositório, automáticamente temos uma branch master e estamos agora nessa branch. Trocar de branches é como trocar de pastas, você precisa rodar um comando para criar elas e outro para ir para essa branch. Neste momento não vamos trocar de branch, vamos somente inicializar o repositório.
Se fossemos trabalhar com um repositório remoto (um repositório que está hospedado em um servidor) seria necessário utilizar o comando git clone para baixar este projeto ao invés de começar um do zero, mas em breve vamos conhecer melhor sobre trabalhar com repositórios remotos.
Agora que temos um repositório, precisamos entender os estágios da utilização do Git.
Estados do nosso trabalho com Git
No Git temos três estados em que nosso código pode estar dentro de um repositório. Esses estados são como pastas ou ramificações mantidas pelo próprio Git. Podemos ver esses estados nessa imagem:
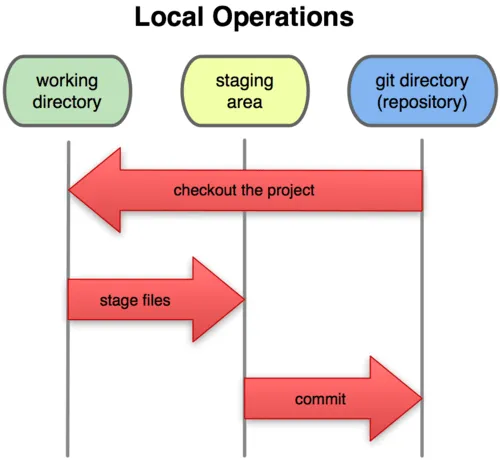
Onde temos: working directory, staging area, git directory e suas operações (de working directory para staging e de staging para git directory e do git directory de volta para staging e working dir).
Vamos entender melhor sobre isso agora.
Working Directory
O working directory possui o estado atual do nosso código. Aquilo que estamos alterando neste exato momento.
Staging Area
A staging area é uma área de preparação antes de fechar um commit de fato. Nós podemos enviar alterações para o stage e continuar trabalhando em nosso código ao invés de fazer um commit por vez e precisar voltar commits. Podemos somente trabalhar de working para stage e de stage para working até que nosso trabalho esteja completamente pronto e assim fechamos um commit.
Git Directory
Este é de fato o nosso histórico. É onde o Git guarda todos os nossos commits e são eles que são enviados para o repositório remoto e compartilhado com outras pessoas. Nem o working directory, nem o stage são compartilhados, esses são estados locais. O Git directory é de fato o nosso banco de objetos do Git.
Checando o estado do nosso código
Para analisarmos em que estado está o nosso código, podemos rodar o comando git status.
Se rodarmos este comando no repositório que acabamos de criar, não teremos nada e a mensagem de retorno será algo como:
➜ workspace git:(master) git status
On branch master
No commits yet
nothing to commit (create/copy files and use "git add" to track)O Git está nos informando que estamos na branch master (On branch master), que não temos nenhum commit (No commits yet) e que não temos nada para fechar um commit, nenhum arquivo para acompanhar (nothing to commit (create/copy files and use "git add" to track)).
Vamos criar um arquivo neste repositório para entender o status. Execute o comando: echo "meu primeiro commit" > exercicio-de-git.txt (se você rodar o comando ls depois deste comando, verá que o arquivo exercicio-de-git.txt foi criado e se executar um cat exercicio-de-git.txt verá o conteúdo deste arquivo). Em seguida execute git status.
A saída do git status será algo como:
➜ workspace git:(master) ✗ git status
On branch master
No commits yet
**Untracked files:
(use "git add <file>..." to include in what will be committed)
exercicio-de-git.txt**
nothing added to commit but untracked files present (use "git add" to track)Perceba que agora o Git nos fala que temos arquivos que não estão sendo acompanhados (Untracked files) e o próprio Git nos ensina a adicionar estes arquivos no staging area ((use "git add <file>..." to include in what will be committed)).
Vamos partir para a prática de adicionar arquivos ao stage.
Adicionando arquivos para criar um commit
Ainda no nosso workspace, vamos agora fazer o que o Git nos sugeriu. Vamos rodar o comando git add.
O comando git add adiciona os arquivos em stage para preparar eles para um commit.
A sintaxe desse comando é: git add nome_do_arquivo.
Vamos então adicionar o exercicio-de-git.txt. Execute:
git add exercicio-de-git.txtEm seguida execute o comando git status. A saída do comando será algo como:
➜ workspace git:(master) ✗ git add exercicio-de-git.txt
➜ workspace git:(master) ✗ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: exercicio-de-git.txtAgora o Git nos informa que temos alterações para consolidar (Changes to be committed). Ele também diz que podemos remover o arquivo com o comando git rm --cached <file>, então, se adicionamos o arquivo em stage sem querer, podemos remover. Se não foi sem querer, então podemos partir para a consolidação (fechar um commit).
Criando o commit
Temos o nosso arquivo sendo acompanhado (tracked) pelo Git adicionado em stage. Sabemos que queremos sim guardar uma versão deste arquivo para enviar para outras pessoas ou mesmo para deixar guardado no histórico, podemos então rodar o comando git commit.
A sintaxe desse comando é: git commit -m "uma legenda para o seu commit".
Lembre-se de colocar mensagens descritivas na legenda do seu commit, pois isso fará toda diferença se algum dia você precisar reverter algo que foi feito.
Vamos fechar nosso primeiro commit com o comando git commit -m "adiciona o arquivo exercicio-de-git.txt".
➜ workspace git:(master) ✗ git commit -m "adiciona o arquivo exercicio-de-git.txt"
[master (root-commit) 2d8e299] adiciona o arquivo exercicio-de-git.txt
1 file changed, 1 insertion(+)
create mode 100644 exercicio-de-git.txtVamos entender a saída do comando git commit. Ele nos informa que na branch master [master, foi adicionado um commit identificado pelo código 2d8e299 e ele carrega a seguinte mensagem de commit adiciona o arquivo exercicio-de-git.txt. Em seguida o Git nos informa que tivemos somente um arquivo alterado com uma única linha sendo adicionada 1 file changed, 1 insertion(+). Ele também avisa que foi criado o arquivo exercicio-de-git.txt create mode 100644 exercicio-de-git.txt.
E agora rode um git status para verificar como está o nosso working dir.
➜ workspace git:(master) git status
On branch master
nothing to commit, working tree cleanTudo está como antes, mas agora ele avisa que não temos nada para consolidar um commit, pois o working directory (working tree) está limpo nothing to commit, working tree clean.
Cadê o nosso commit então?
Lendo o histórico do Git
Assim que nosso commit foi realmente fechado, o Git moveu as alterações para o Git Directory e agora temos um comando que nos ajuda a ver o que tem lá dentro. Este comando é o git log.
Vamos verificar como está o log do nosso workspace. Execute o comando git log. A saída do comando será algo como:
commit 2d8e299718ca35f518f6488a14d421cf9ced30ea (HEAD -> master)
Author: William Oliveira <contato@woliveiras.dev>
Date: Sun Mar 24 10:22:55 2019 -0300
adiciona o arquivo exercicio-de-git.txt
(END)Mas, claro, com outro nome de autor, email, data e id (identificador) do commit.
Se houvesse mais commits, iria aparecer uma lista muito maior. Para sair do leitor de histórico do Git, basta pressionar a letra q no seu teclado.
Criando branches
Agora imagina que queremos criar uma área de testes antes de consolidar nosso trabalho na branch master. Vamos então utilizar o comando git checkout para criar e trocar de branch para que o histórico da master não fique “feio”. Lembre: o histórico é algo muito importante e funciona como uma documentação do nosso código, por isso não deixe ele ficar ruim.
A sintaxe do comando git checkout, para criar uma branch e mudar para ela, é: git checkout -b nome_da_branch. Rodamos o comando git checkout com o parâmetro -b e o nome da branch que será criada. Se desejamos trocar de uma branch para a outra, rodamos somente o git checkout nome_da_branch.
O comando checkout além de trocar de branchs, poderia também reverter nosso código para uma versão anterior se utilizarmos, ao invés do nome de uma branch, o hash (id) de um commit antigo. Mas por enquanto foque em criar a branch, vamos aprender a reverter nosso trabalho mais abaixo.
Vamos criar uma branch chamada “arquivo-com-meu-nome”, pois essa será a nossa tarefa; “adicionar um arquivo com meu nome”.
git checkout -b arquivo-com-meu-nomeAo executar este comando, podemos rodar um git status e verificar que estamos agora em outra branch, não a master. Estamos na branch que acabamos de criar.
➜ workspace git:(arquivo-com-meu-nome) git status
On branch arquivo-com-meu-nome
nothing to commit, working tree cleanRepare na mensagem “On branch arquivo-com-meu-nome”.
Agora podemos adicionar nosso trabalho ao histórico. Vamos criar um arquivo com nosso nome, adicionar ao stage e fechar um commit.
Estes são os comandos para essa tarefa:
- echo “meu nome é William Oliveira” > william.txt
- git status
- git add william.txt
- git commit -m “adiciona o arquivo com meu nome”
- git status
➜ workspace git:(arquivo-com-meu-nome) echo "meu nome é William Oliveira" > william.txt
➜ workspace git:(arquivo-com-meu-nome) ✗ git status
On branch arquivo-com-meu-nome
Untracked files:
(use "git add <file>..." to include in what will be committed)
william.txt
nothing added to commit but untracked files present (use "git add" to track)
➜ workspace git:(arquivo-com-meu-nome) ✗ git add william.txt
➜ workspace git:(arquivo-com-meu-nome) ✗ git commit -m "adiciona o arquivo com meu nome"
[arquivo-com-meu-nome 58cffab] adiciona o arquivo com meu nome
1 file changed, 1 insertion(+)
create mode 100644 william.txt
➜ workspace git:(arquivo-com-meu-nome) git status
On branch arquivo-com-meu-nome
nothing to commit, working tree clean
➜ workspace git:(arquivo-com-meu-nome)Vamos rodar o comando git log para conferir nosso histórico.
Dessa vez eu vou executar como git log --oneline, para que o histórico apareça somente com a mensagem de commit, não mais com todos os detalhes.
➜ workspace git log --onelineO retorno é algo como:
58cffab (HEAD -> arquivo-com-meu-nome) adiciona o arquivo com meu nome
e58c52f (master) adiciona o arquivo exercicio-de-git.txt
(END)Repare que agora temos o nosso commit na branch “arquivo-com-meu-nome”: (HEAD -> arquivo-com-meu-nome) adiciona o arquivo com meu nome.
Você pode sair do histórico pressionando o q.
Vamos mudar para a branch master para conferir o histórico dela.
Lembra que o comando git checkout serve para trocar de branches?
Execute:
git checkout masterAgora vamos olhar o histórico.
Execute:
git log --onelineNa saída do git log não temos mais o commit que acabamos de criar.
e58c52f (HEAD -> master) adiciona o arquivo exercicio-de-git.txt
(END)Se você rodar um ls, vai perceber que o arquivo que acabamos de criar também não existe na master.
Isso acontece porque o nosso commit está na outra branch e, para que ele venha para a master, precisamos rodar um comando que junta os commits de uma branch em outra.
Juntando branches
Agora que temos duas branches, uma com um commit a mais do que a outra, precisamos unir as duas para formar de volta nosso histórico ideal (também com os arquivos que acabamos de criar).
Para juntar duas branches, precisamos rodar o comando git merge.
A sintaxe do comando é: git merge nome_da_outra_branch.
Para que o git merge funcione, precisamos estar na branch que irá receber os commits da outra. No nosso exemplo, para receber o novo commit da branch arquivo-com-meu-nome na master, precisamos estar na master.
Para isso precisaríamos do comando git checkout master, mas nós já rodamos ele no passo anterior. Agora podemos executar diretamente o git merge.
git merge arquivo-com-meu-nomeRepare que, ao rodar este comando, temos a seguinte saída no terminal:
➜ workspace git:(master) git merge arquivo-com-meu-nome
Updating e58c52f..58cffab
Fast-forward
william.txt | 1 +
1 file changed, 1 insertion(+)
create mode 100644 william.txtEle diz que a nossa branch foi atualizada, recebendo um outro commit, com mais um arquivo com uma linha adicionada, assim como na parte em que aprendemos sobre criação de commits.
Vamos verificar o histórico com o nosso comando git log --oneline.
git log --onelineO retorno do comando será algo como:
58cffab (HEAD -> master, arquivo-com-meu-nome) adiciona o arquivo com meu nome
e58c52f adiciona o arquivo exercicio-de-git.txt
(END)Se rodarmos o comando ls agora, veremos que o arquivo com o nosso nome está na pasta novamente.
➜ workspace git:(master) ls
exercicio-de-git.txt william.txtO que aconteceu aqui foi que o Git pegou o commit 58cffab, que é o id do nosso commit que estava na outra branch e trouxe para a que rodamos o comando git merge.
Deletando branches
Agora que nosso trabalho na branch arquivo-com-meu-nome está concluído, pois já fizemos o merge na master, podemos então deletar ela, pois ela não servirá para mais nada.
Para sabermos quantas branches temos em nosso repositório, podemos rodar o comando git branch.
git branchSerá feita uma listagem parecida com essa:
arquivo-com-meu-nome
* master
(END)O asterísco ( * ) informa em qual branch estamos neste momento.
Para deletar uma branch, rodamos o comando git branch -d nome_da_branch. Bem parecido com o git checkout, quando passamos o parâmetro -d no git branch, ao invés de listar as branches, ele deleta a que informarmos.
➜ workspace git:(master) git branch -d arquivo-com-meu-nome
Deleted branch arquivo-com-meu-nome (was 58cffab).Recebemos uma saída informando que nossa branch foi deletada.
Deleted branch arquivo-com-meu-nome (was 58cffab).Revertendo as coisas
Imagine agora que, as alterações que nós acabamos de fazer estragaram o nosso código. Juntar o arquivo que veio da branch arquivo-com-meu-nome fez com que o nosso software saísse do ar. Agora que vemos todo o poder do versionamento de código. Podemos reverter essas alterações com o comando revert.
Para reverter o que acabamos de fazer precisaremos rodar o comando git revert numero_do_commit.
Vamos rodar então o git log para pegarmos o hash do commit.
git logRecebemos uma saída parecida com essa:
commit 58cffab5a37d9230c0b48ae3ab5c60d63a48c7d7 (HEAD -> master)
Author: woliveiras <w.oliveira542@gmail.com>
Date: Tue Mar 26 07:21:05 2019 -0300
adiciona o arquivo com meu nome
commit e58c52f2b8ec2b229a32194281fbceb724211775
Author: woliveiras <w.oliveira542@gmail.com>
Date: Tue Mar 26 07:17:03 2019 -0300
adiciona o arquivo exercicio-de-git.txt
(END)Sabemos que o commit que estragou nosso código foi o que veio com a mensagem “adiciona o arquivo com meu nome”. Neste exemplo (no meu repositório) o hash do commit é o 58cffab (não precisamos do código inteiro, somente dos 7 primeiros números). Então basta desfazermos este commit com o comando revert
, como o e58c52f, que é o que recebe a mensagem “adiciona o arquivo exercicio-de-git.tx”. Agora você entende a necessidade de colocar boas mensagens para os commits, não?
Para desfazer o commit 58cffab, vamos rodar:
git revert 58cffabSerá aberto o nosso editor de textos via terminal ou o editor que você configurou para que fosse seu editor padrão do Git, como no caso de usarmos o VS Code para versionamento.
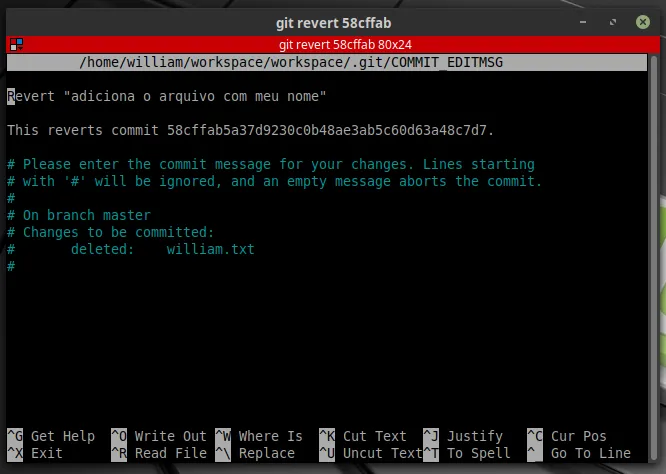
Poderíamos também utilizar o git checkout para fazer essa reversão, porém ele voltaria para um commit anterior, como comentei quando aprendemos o git checkout. Seria necessário criar uma nova branch e fazer o merge com a master. É um processo mais demorado. O revert, além de já trazer uma mensagem descritiva sobre a reversão, é menos trabalhoso.
Caso o comando git revert tenha aberto o NANO (um editor de textos via linha de comando), como na imagem acima, basta você pressionar CTRL+X que o commit com o revert será finalizado.
Agora, se rodarmos o comando git log, temos a saída parecida com isso:
commit 484f0fa22e5cb3e2fc5b9e5722418a17e46e80e0 (HEAD -> master)
Author: woliveiras <w.oliveira542@gmail.com>
Date: Tue Mar 26 08:28:58 2019 -0300
Revert "adiciona o arquivo com meu nome"
This reverts commit 58cffab5a37d9230c0b48ae3ab5c60d63a48c7d7.Temos a nossa mensagem de revert e um novo commit desfazendo as coisas.
Se rodarmos um ls agora, teremos somente o arquivo inicial, não mais o arquivo com meu nome adicionado pela outra branch.
➜ workspace git:(master) ls
exercicio-de-git.txtPodemos também desfazer o nosso trabalho antes mesmo de criar um novo commit e para isso utilizamos o comando git checkout.
Vamos alterar o arquivo exercicio-de-git adicionando mais uma linha no final do arquivo.
Basta rodar um echo “nova linha” >> exercicio-de-git.txt e agora podemos rodar o cat exercicio-de-git e veremos que foi adicionado nosso texto.
➜ workspace git:(master) echo "nova linha" >> exercicio-de-git.txt
➜ workspace git:(master) ✗ cat exercicio-de-git.txt
meu primeiro commit
nova linhaSe rodarmos o git status agora, vemos que existem alterações.
➜ workspace git:(master) ✗ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: exercicio-de-git.txt
no changes added to commit (use "git add" and/or "git commit -a")O próprio Git nos informa que podemos desfazer isso na linha (use “git checkout —
Vamos desfazer então! Execute git checkout -- exercicio-de-git, depois rode um git status e dê um cat exercicio-de-git para confirmar se o arquivo voltou ao que era antes.
➜ workspace git:(master) ✗ git checkout -- exercicio-de-git.txt
➜ workspace git:(master) git status
On branch master
nothing to commit, working tree clean
➜ workspace git:(master) cat exercicio-de-git.txt
meu primeiro commitTambém poderíamos ter feito git checkout master ou git checkout . que faria com que todas as nossas últimas alterações fossem descartadas.
Conclusão
Até aqui aprendemos muito!
Aprendemos instalar e configurar o Git, todos os termos mais importantes como repositórios, commits, histórico, branches, estados no Git, adicionar arquivos no stage, fechar commits, navegar no histórico de uma branch, criar e trocar de branches, unir elas e até como desfazer as coisas.
Você não precisa decorar todos estes comandos, só entender para o que cada um serve, pois tudo isso se torna automático no seu dia-a-dia. Se você esquecer de algum, basta pesquisar no Google ou olhar este artigo (recomendo deixar nos favoritos): Comandos mais utilizados no Git.
O próximo passo é aprendermos a trabalhar com repositórios remotos, onde vamos conhecer o GitHub, GitLab e Bitbucket.
No próximo artigo vamos aprender a utilizar repositórios remotos e o GitHub: Trabalhando com repositórios remotos - Git e GitHub.
Se você gosta do meu conteúdo, não esqueça de contribuir via Apoia.se: Apoia.se: William Oliveira.
Referências
Foto por Pankaj Patel via Unsplash.